Nowa Google Search Console w praktyce – w końcu wiem do czego służą sitemapy
26 marca, 2018
Wojciech Grądzki
Narzędzia SEO
Techniczne SEO
Google niedawno udostępnił nową wersję Search Console, czyli narzędzia służącego do monitorowania obecności naszego serwisu w Google. Nowa wersja narzędzia znajduje się w wersji Beta i posiada bardzo ograniczoną funkcjonalność w stosunku do wersji wcześniejszej. Jedna z nowych funkcji okazuje się jednak bardzo przydatna.
Brak sitemapy serwisu często wskazywana jest jako poważny błąd w optymalizacji SEO serwisu. Czy słusznie? Sitemapy pozwalają na poinformowanie Google o liście stron w naszym serwisie i tyle. Ich obecność nie ma żadnego wpływu na pozycję danej strony. Jedyna korzyść z sitemapy to fakt, że google jest w stanie dotrzeć do stron, do których nie znajdzie odnośników w serwisie. Jednak strony bez linków wewnętrznych nie mają szans na dobrą pozycję, a sam fakt ich obecności w indeksie Google nie stanowi żadnej wartości. Jeśli strona posiada dobrze zorganizowaną strukturę linkowania wewnętrznego, tzn. jeśli wszystkie strony, które chcemy mieć obecne w indeksie Google są dostęne przy pomocy statycznych odnośników html, a ścieżka dojścia do nich nie jest zbyt odległa, obecność sitemap nie przynosi żadnych korzyści.
Przez lata, nieco na przekór wszelkim poradnikom i wytycznym, z reguły nie stosowałem sitemap wychodząc z założenia, że skoro nie widać różnicy to po co przepłacać. Sytuacja uległa znany zmianie wraz z wprowadzeniem nowej wersji Google Search Console o czym przekonaliśmy się w ostatnim czasie.
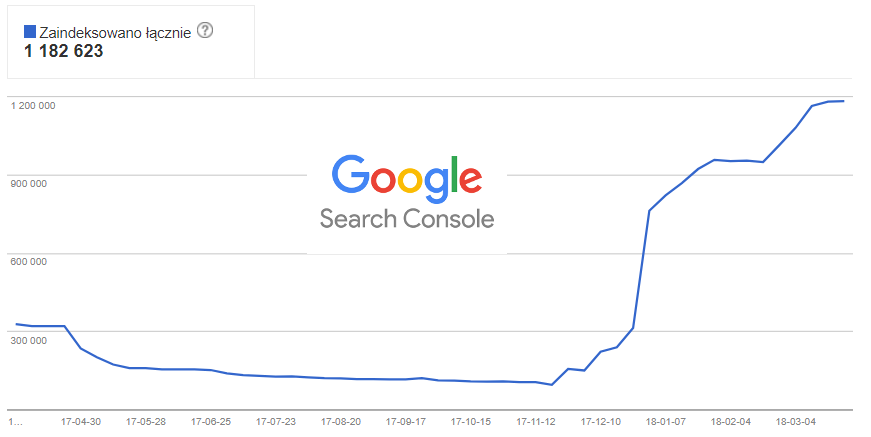
Mamy przypadek dosyć rozbudowanej strony dla, której przygotowaliśmy ok. 400 tys. stron, które powinny znaleźć się w indeksie Google. Nieco wbrew swoim zasadom, w tym przypadku, ze względu na wielkość serwisu i nieco zagmatwaną strukturę, uznaliśmy, że warto wystawić Google’owi sitemapę. Po ok. miesiącu Google ładnie zaindeksował praktycznie wszystkie strony z sitemapy. Po kilku kolejnych dniach zauważyliśmy, że ilość stron w indeksie wciąż rośnie by zatrzymać się dopiero na ok. 1,2 mln:
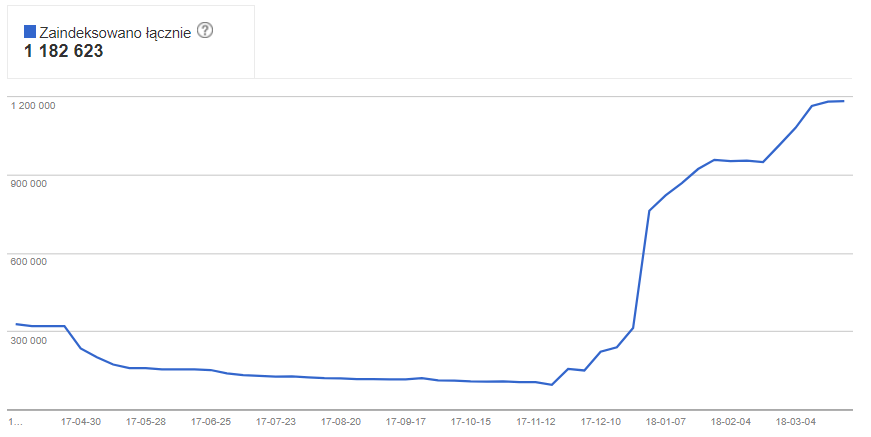
Oznacza to, że robot Google „wszedł w maliny”, czyli zaindeksował strony, których nie powinien, a więc najczęściej strony nie zawierające unikalnej, wartościowej treści. Obecność w indeksie tak dużej liczby niechcianych stron, zdecydowanie jest niekorzystna, stanowi zagrożenie objęcia serwisu algorytmem Panda, który karze serwisy zawierające dużą liczbę bezwartościowych stron. W najlepszym przypadku, takie strony zjadają nam crawl budget, czyli marnują czas robota Google na pobieranie bezwartościowych stron, przez co rzadziej pobierane są prawidłowe strony. W każdym razie, zaistenienie tego typu sytuacji wymaga dokładnej diagnozy.
Zazwyczaj diagnoza tego problemu jest dość prosta – wystarczy przeszukać serwis z operatorem „site:”, kliknąć którąś z dalszych ston wyników wyszukiwania aby zobaczyć cóż to za śmieci znalazły się w indeksie. Jeśli widzimy tam poprawne adresy, można je wykluczyć z wynikiem z operatorem „-inurl:fragment_poprawnego-adresu” czy też ograniczając wyszukiwanie do stron zaindeksowanych w określonym czasie. W tym jednak wypadku zadanie okazało się trudne – w żaden z tego typów sposobów nie mogłem odnaleźć nieprawidłowych adresów. Z pewnością zadania nie ułatwiał fakt, że serwis stosuje specyficzny sposób budowania urli, z kilkoma dużymi liczbami poprzedzonymi przecinkami.
Jak rozwiażać taki problem? Możemy wykorzystać jakieś narzędzie do crawlowania serwisu typu Deep Crawl a potem zestawić listę znalezionych stron z listą stron o których wiemy. Ok, to jest jakieś rozwiązanie, ale tego typu narzędzia zazwyczaj są płatne no i trochę by to zajęło, jeśli Google znalazł na stronie ponad 1 mln podstron.
Pomysłem, który prawie udało się zrealizować była analiza acceslogów serwisu i porównanie listy urli pobranych przez Robota Google z listą stron z sitemapy. Nie posiadamy bezpośredniego dostępu do logów serwisu i musieliśmy się posiłkować pomocą ludzi z IT. Nie potraktowali naszej prośby priorytetowo, dlatego ostatecznie nie wykonaliśmy takiej analizy.
W międzyczasie serwis otrzymał dostęp do nowej Google Search Console. Co ciekawe, to był nasz ostatni serwis, który jeszcze takiego dostępu nie miał – pewnie decydowała o tym jego wielkość. Szybkie zerknięcie do nowej konsoli na stronę z listą stron, które są w indeksie a których nie ma w sitemapie i bingo, wiemy dokładnie jakiego rodzaju strony indeksuje, choć nie powinien.
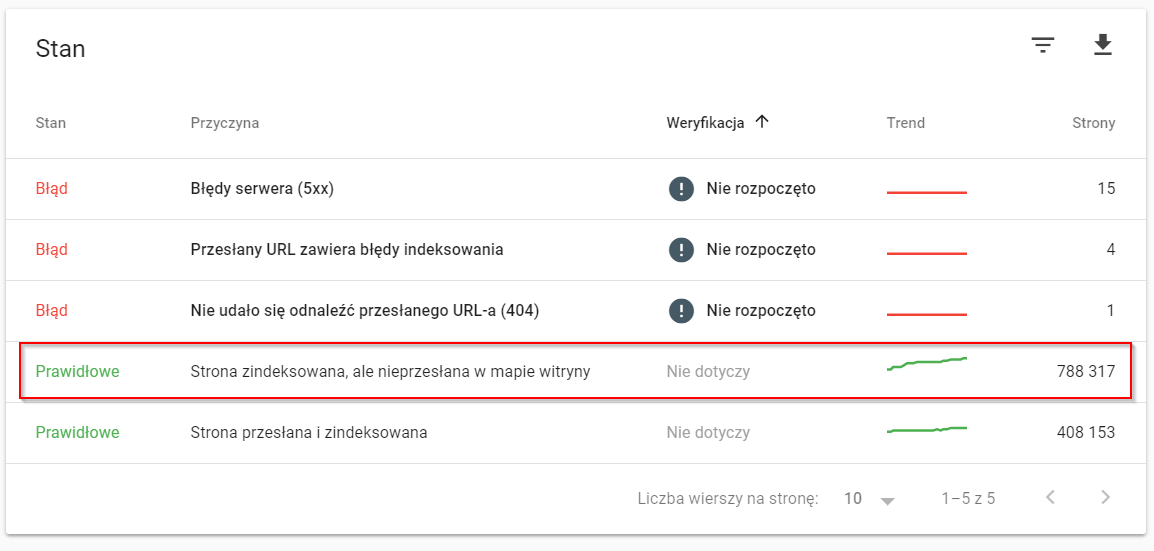
Znając dokładne adresy, stosunkowo szybko jesteśmy w stanie namierzyć źródło problemu – oczywiście gdzieś głęboko w serwisie znajdowały się linki do tych stron.
Nowa Search Console, choć jest jeszcze w wersji Beta, już w tej chwili pomaga rozwiązać problemy, które do tej pory wymagały użycia zewnętrznych narzędzi. Nie możemy doczekać się kolejnych aktualizacji.
Tak przy okazji – serwis o którym piszę to jeden z ciekawszych projektów nad którym pracujemy. Wkrótce opiszemy case dokładnie, na razie garść kluczowych faktów:
- Serwis rozwijany i „pozycjonowany” od początku 2015 roku z dosyć mizernym skutkiem
- W lipcu 2017 rozpoczęliśmy współpracę
- Liczba stron w sitemapie – spadek z 40 mln (sic!) do 400 tys.
- Wzrost liczby fraz w top10 wg senuto po 9 miesięcach współpracy: + 500%:
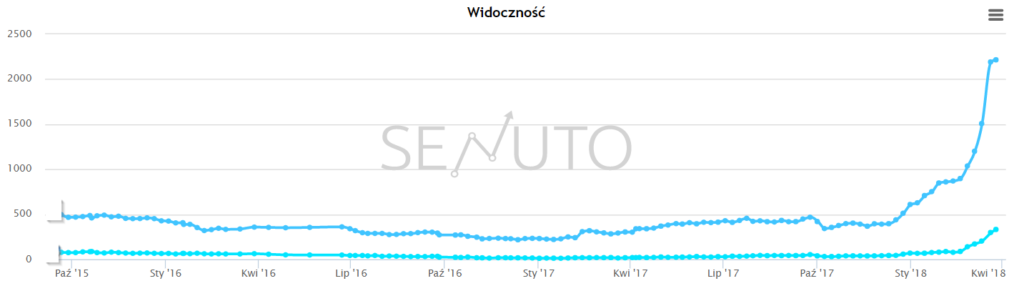
Pełna analizę zrobimy za jakiś czas, mamy jeszcze kilka pomysłów na dalsze wzrosty tego serwisu.

Autor wpisu
Wojciech Grądzki
Przez 17 lat pracował w Wirtualnej Polsce, od początku przy wyszukiwarkach a przez 10 ostatnich lat kierował działaniami SEO Grupy WP pracując przy wp.pl, o2.pl, money.pl, abczdrowie.pl, SportoweFakty, Pudelek. Od 2017 roku, wspólnie ze współpracownikiem z WP, Tomkiem Mielewczykiem prowadzi agencję SAMOSEO.
6 komentarzy
-
-
W sitemapie było 40 mln dokumentów o praktycznie identycznej treści. Odchudziliśmy to do 400 tys znacznie wzbogacając i różnicując zawartość tych stron. Samo usunięcie śmieci z indeksu nic pewnie by nie dało, bo w serwisie nie było praktycznie stron o unikalnej zawartości w formie przyjaznej dla Google. Jako ciekawostkę mogę dodać fakt, że serwis serwował w sitemapie 40 mln urli, z czego Google indeksował ok. 100 tys. Zostawiliśmy z tego 400 tys i Google zaindeksował … 1,2 mln. Oczywiście jak pisałem, zawartość tych stron się zmieniła, co miało kluczowe znaczenie. W serwisie wprowadziliśmy pewnie z kilkadziesiąt już zmian, to wszystko przełożyło się na osiągnięty efekt.
-
-
Sitemapy zawsze lepiej mieć niż nie mieć. Chociaż możliwe, że przy małych stronach różnica nie będzie widoczna. Dzięki za artykuł! Zachęcam do dodania go na https://facebook.com/groups/773447096146126 🙂
-
Nowe GSC robi robotę, w przypadku sitemap jesteśmy w stanie wyeliminować więcej problemów niż kiedykolwiek.
-
Dzięki za wyczerpującą wstawkę 🙂 Chociaż wgłębiając się w szczegóły google search console to ma to ułatwić/przyspieszyć indeksowanie naszej strony. Generalnie nawet nie trzeba korzystać z tego narzędzia.
-
Bardzo fajny i wartościowy case, pokazujący jak specjaliści SEO mimo szczątkowych danych, które dostają mogą pracować (mimo, że można by lepiej gdyby prośby były traktowane poważnie a nie na poziomie, a to specjaliści od tytułów i spamotreści). Smutne jest że przypadek opisywany we wpisie o ile nie wydarzy się na żywo to przez większość developerów a nie mówiąc już o klientach zostanie zbagatelizowany. Pozdrawiam.
Dodaj komentarz
Powiązane artykuły

Monika Król

SAMOSEO

Jaki wpływ na ilość fraz w top10 miała ilość stron z thin content w indeksie?